NGINX的upstream容错
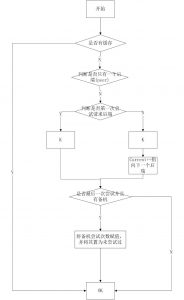
Nginx 判断节点失效状态
Nginx默认判断失败节点状态以connect refuse和time out状态为准,不以HTTP错误状态进行判断失败,因为HTTP只要能返回状态说明该节点还可以正常连接,所以nginx判断其还是存活状态;除非添加了proxy_next_upstream指令设置对404、502、503、504、500和time out等错误进行转到备机处理,在next_upstream过程中,会对fails进行累加,如果备用机处理还是错误则直接返回错误信息(但404不进行记录到错误数,如果不配置错误状态也不对其进行错误状态记录),综述,nginx记录错误数量只记录timeout 、connect refuse、502、500、503、504这6种状态,timeout和connect refuse是永远被记录错误状态,而502、500、503、504只有在配置proxy_next_upstream后nginx才会记录这4种HTTP错误到fails中,当fails大于等于max_fails时,则该节点失效;
nginx 处理节点失效和恢复的触发条件
nginx可以通过设置max_fails(最大尝试失败次数)和fail_timeout(失效时间,在到达最大尝试失败次数后,在fail_timeout的时间范围内节点被置为失效,除非所有节点都失效,否则该时间内,节点不进行恢复)对节点失败的尝试次数和失效时间进行设置,当超过最大尝试次数或失效时间未超过配置失效时间,则nginx会对节点状会置为失效状态,nginx不对该后端进行连接,直到超过失效时间或者所有节点都失效后,该节点重新置为有效,重新探测;
所有节点失效后nginx将重新恢复所有节点进行探测
如果探测所有节点均失效,备机也为失效时,那么nginx会对所有节点恢复为有效,重新尝试探测有效节点,如果探测到有效节点则返回正确节点内容,如果还是全部错误,那么继续探测下去,当没有正确信息时,节点失效时默认返回状态为502,但是下次访问节点时会继续探测正确节点,直到找到正确的为止。
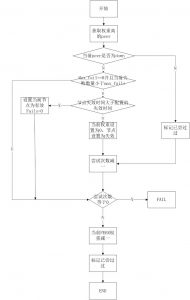
通过proxy_next_upstream实现容灾和重复处理问题
ngx_http_proxy_module 模块中包括proxy_next_upstream指令
语法: proxy_next_upstream error | timeout | invalid_header | http_500 | http_502 | http_503 | http_504 |http_404 | off …;
默认值: proxy_next_upstream error timeout; 上下文: http, server, location其中:
error 表示和后端服务器建立连接时,或者向后端服务器发送请求时,或者从后端服务器接收响应头时,出现错误。
timeout 表示和后端服务器建立连接时,或者向后端服务器发送请求时,或者从后端服务器接收响应头时,出现超时。
invalid_header 表示后端服务器返回空响应或者非法响应头
http_500 表示后端服务器返回的响应状态码为500
http_502 表示后端服务器返回的响应状态码为502
http_503 表示后端服务器返回的响应状态码为503
http_504 表示后端服务器返回的响应状态码为504
http_404 表示后端服务器返回的响应状态码为404
off 表示停止将请求发送给下一台后端服务器运用场景
1)proxy_next_upstream http_500 | http_502 | http_503 | http_504 |http_404; 当其中一台返回错误码404,500...等错误时,可以分配到下一台服务器程序继续处理,提高平台访问成功率,多可运用于前台程序负载,设置 2、proxy_next_upstream off 因为proxy_next_upstream 默认值: proxy_next_upstream error timeout; 场景: 当访问A时,A返回error timeout时,访问会继续分配到下一台服务器处理,就等于一个请求分发到多台服务器,就可能出现多次处理的情况, 如果涉及到充值,就有可能充值多次的情况,这种情况下就要把proxy_next_upstream关掉即可 proxy_next_upstream off 案例分析(nginx proxy_next_upstream导致的一个重复提交错误): 一个请求被重复提交,原因是nginx代理后面挂着2个服务器,请求超时的时候(其实已经处理了),结果nigix发现超时,有把请求转给另外台服务器又做了次处理。 解决办法: proxy_next_upstream:offnginx负载均衡
Nginx的负载均衡方式这里介绍4种:rr(轮询模式)、ip_hash、fair、url_hash;
Nginx自带的2种负载均衡为rr和ip_hash,fair和url_hash为第三方的插件,nginx在不配置负载均衡的模式下,默认采用rr负载均衡模式。
1)RR负载均衡模式:
每个请求按时间顺序逐一分配到不同的后端服务器,如果超过了最大失败次数后(max_fails,默认1),在失效时间内(fail_timeout,默认10秒),该节点失效权重变为0,超过失效时间后,则恢复正常,或者全部节点都为down后,那么将所有节点都恢复为有效继续探测,一般来说rr可以根据权重来进行均匀分配。
2)Ip_hash负载均衡模式:
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题,但是ip_hash会造成负载不均,有的服务请求接受多,有的服务请求接受少,所以不建议采用ip_hash模式,session共享问题可用后端服务的session共享代替nginx的ip_hash。
3)Fair(第三方)负载均衡模式:
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
4)url_hash(第三方)负载均衡模式:
和ip_hash算法类似,是对每个请求按url的hash结果分配,使每个URL定向到一个同 一个后端服务器,但是也会造成分配不均的问题,这种模式后端服务器为缓存时比较好。Nginx负载均衡配置
Nginx的负载均衡采用的是upstream模块,其中默认的采用的负载均衡模式是轮询模式rr(round_robin),具体配置如下:
1)指令:
ip_hash
语法:ip_hash
默认值:none
使用字段:upstream
这个指令将基于客户端连接的IP地址来分发请求。
哈希的关键字是客户端的C类网络地址,这个功能将保证这个客户端请求总是被转发到一台服务器上,但是如果这台服务器不可用,那么请求将转发到另外的服务器上,这将保证某个客户端有很大概率总是连接到一台服务器。
无法将权重(weight)与ip_hash联合使用来分发连接。如果有某台服务器不可用,你必须标记其为”down”,如下例:upstream backend { ip_hash; server backend1.kevin.com; server backend2.kevin.com; server backend3.kevin.com down; server backend4.kevin.com; }server
语法:server name [parameters]
默认值:none
使用字段:upstream
指定后端服务器的名称和一些参数,可以使用域名,IP,端口,或者unix socket。如果指定为域名,则首先将其解析为IP。
[1] weight = NUMBER – 设置服务器权重,默认为1。
[2] max_fails = NUMBER – 在一定时间内(这个时间在fail_timeout参数中设置)检查这个服务器是否可用时产生的最多失败请求数,默认为1,将其设置为0可以关闭检查,这些错误在proxy_next_upstream或fastcgi_next_upstream(404错误不会使max_fails增加)中定义。
[3] fail_timeout = TIME – 在这个时间内产生了max_fails所设置大小的失败尝试连接请求后这个服务器可能不可用,同样它指定了服务器不可用的时间(在下一次尝试连接请求发起之前),默认为10秒,fail_timeout与前端响应时间没有直接关系,不过可以使用proxy_connect_timeout和proxy_read_timeout来控制。
[4] down – 标记服务器处于离线状态,通常和ip_hash一起使用。
[5] backup – (0.6.7或更高)如果所有的非备份服务器都宕机或繁忙,则使用本服务器(无法和ip_hash指令搭配使用)。实例配置
upstream backend { server backend1.kevin.com weight=5; server 127.0.0.1:8080 max_fails=3 fail_timeout=30s; server unix:/tmp/backend3; }注意:如果你只使用一台上游服务器,nginx将设置一个内置变量为1,即max_fails和fail_timeout参数不会被处理。
结果:如果nginx不能连接到上游,请求将丢失。
解决:使用多台上游服务器。upstream
语法:upstream name { … }
默认值:none
使用字段:http
这个字段设置一群服务器,可以将这个字段放在proxy_pass和fastcgi_pass指令中作为一个单独的实体,它们可以可以是监听不同端口的服务器,并且也可以是同时监听TCP和Unix socket的服务器。
服务器可以指定不同的权重,默认为1。
示例配置upstream backend { server kevin.com weight=5; server 127.0.0.1:8080 max_fails=3 fail_timeout=30s; server unix:/tmp/backend3; }请求将按照轮询的方式分发到后端服务器,但同时也会考虑权重。
在上面的例子中如果每次发生7个请求,5个请求将被发送到backend1.kevin.com,其他两台将分别得到一个请求,如果有一台服务器不可用,那么请求将被转发到下一台服务器,直到所有的服务器检查都通过。如果所有的服务器都无法通过检查,那么将返回给客户端最后一台工作的服务器产生的结果。2) 变量
版本0.5.18以后,可以通过log_module中的变量来记录日志:
log_format timing ‘$remote_addr – $remote_user [$time_local] $request ‘
‘upstream_response_time $upstream_response_time ‘
‘msec $msec request_time $request_time’;log_format up_head ‘$remote_addr – $remote_user [$time_local] $request ‘
‘upstream_http_content_type $upstream_http_content_type’;$upstream_addr
前端服务器处理请求的服务器地址$upstream_cache_status
显示缓存的状态nginx在web应用上的占用率越来越高,其带的模块也越来越来。nginx_cache算是一个,虽和专业的cache工具相比略逊一筹,但毕竟部署简单,不用另装软件
和资源开销,所以在web cache中也占了比重不小的一席。不过像squid和varnish等cache软件都自带的有cache查看工具,而且还可以方便的在http header上
显示出是否命中。nginx主要还是做web使用。所以想要得出命中率的大小,还需要通过日志进行统计,不过想要增加header查看倒很简单1)在http header上增加命中显示
nginx提供了$upstream_cache_status这个变量来显示缓存的状态,我们可以在配置中添加一个http头来显示这一状态,达到类似squid的效果。
location / {
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_connect_timeout 180;
proxy_send_timeout 180;
proxy_read_timeout 180;
proxy_buffer_size 128k;
proxy_buffers 4 128k;
proxy_busy_buffers_size 128k;
proxy_temp_file_write_size 128k;
proxy_cache cache;
proxy_cache_valid 200 304 1h;
proxy_cache_valid 404 1m;
proxy_cache_key $uri$is_args$args;
add_header Nginx-Cache “$upstream_cache_status”;
proxy_pass http://backend;
}而通过curl或浏览器查看到的header如下:
HTTP/1.1 200 OK
Date: Mon, 22 Apr 2013 02:10:02 GMT
Server: nginx
Content-Type: image/jpeg
Content-Length: 23560
Last-Modified: Thu, 18 Apr 2013 11:05:43 GMT
Nginx-Cache: HIT
Accept-Ranges: bytes
Vary: User-Agent$upstream_cache_status包含以下几种状态:
·MISS 未命中,请求被传送到后端
·HIT 缓存命中
·EXPIRED 缓存已经过期请求被传送到后端
·UPDATING 正在更新缓存,将使用旧的应答
·STALE 后端将得到过期的应答
=======================================================================================================================
nginx比较强大,可以针对单个域名请求做出单个连接超时的配置. 可以根据业务的:proxy_connect_timeout :后端服务器连接的超时时间_发起握手等候响应超时时间
proxy_read_timeout:连接成功后,等候后端服务器响应时间_其实已经进入后端的排队之中等候处理(也可以说是后端服务器处理请求的时间)
proxy_send_timeout :后端服务器数据回传时间_就是在规定时间之内后端服务器必须传完所有的数据
$upstream_status
前端服务器的响应状态。$upstream_response_time
前端服务器的应答时间,精确到毫秒,不同的应答以逗号和冒号分开。$upstream_http_$HEADER
随意的HTTP协议头,如:$upstream_http_host$upstream_http_host
Proxy指令
proxy_next_upstream
语法:proxy_next_upstream
[error|timeout|invalid_header|http_500|http_502|http_503|http_504|http_404|off]默认值:proxy_next_upstream error timeout
使用字段:http, server, location确定在何种情况下请求将转发到下一个服务器:
error 在连接到一个服务器,发送一个请求,或者读取应答时发生错误。
timeout 在连接到服务器,转发请求或者读取应答时发生超时。
invalid_header 服务器返回空的或者错误的应答。
http_500 服务器返回500代码。
http_502 服务器返回502代码。
http_503 服务器返回503代码。
http_504 服务器返回504代码。
http_404 服务器返回404代码。
off 禁止转发请求到下一台服务器。转发请求只发生在没有数据传递到客户端的过程中。
其中记录到nginx后端错误数量的有500、502、503、504、timeout,404不记录错误。proxy_connect_timeout
语法:proxy_connect_timeout timeout_in_seconds
默认值:proxy_connect_timeout 60s
使用字段:http, server, location
指定一个连接到代理服务器的超时时间,单位为秒,需要注意的是这个时间最好不要超过75秒。
这个时间并不是指服务器传回页面的时间(这个时间由proxy_read_timeout声明)。
如果你的前端代理服务器是正常运行的,但是遇到一些状况(如没有足够的线程去处理请求,请求将被放在一个连接池中延迟处理),那么这个声明无助于服务器去建立连接。
可以通过指定时间单位以免引起混乱,支持的时间单位有”s”(秒), “ms”(毫秒), “y”(年), “M”(月), “w”(周), “d”(日), “h”(小时),和 “m”(分钟)。
这个值不能大于597小时。proxy_read_timeout
语法:proxy_read_timeout time
默认值:proxy_read_timeout 60s
使用字段:http, server, location
决定读取后端服务器应答的超时时间,单位为秒,它决定nginx将等待多久时间来取得一个请求的应答。超时时间是指完成了两次握手后并且状态为established的超时时间。
相对于proxy_connect_timeout,这个时间可以扑捉到一台将你的连接放入连接池延迟处理并且没有数据传送的服务器,注意不要将此值设置太低,某些情况下代理服务器将花很长的时间来获得页面应答(例如如当接收一个需要很多计算的报表时),当然你可以在不同的location里面设置不同的值。
可以通过指定时间单位以免引起混乱,支持的时间单位有”s”(秒), “ms”(毫秒), “y”(年), “M”(月), “w”(周), “d”(日), “h”(小时),和 “m”(分钟)。
这个值不能大于597小时。proxy_send_timeout
语法:proxy_send_timeout seconds
默认值:proxy_send_timeout 60s
使用字段:http, server, location
设置代理服务器转发请求的超时时间,单位为秒,同样指完成两次握手后的时间,如果超过这个时间代理服务器没有数据转发到被代理服务器,nginx将关闭连接。
可以通过指定时间单位以免引起混乱,支持的时间单位有”s”(秒), “ms”(毫秒), “y”(年), “M”(月), “w”(周), “d”(日), “h”(小时),和 “m”(分钟)。
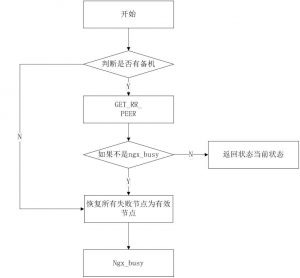
这个值不能大于597小时。Nginx upstream负载均衡获取后端服务器的流程
GET_RR_PEER: 通过RR算法获取后端流程
K:是判断peer是否宕机和判断失效状态算法
FAIL:尝试次数用尽有,跳转到失败流程,如果有备机,备机再尝试监听,如果监听失败则返回NGX_BUSY,成功则返回当前状态。
五、验证环境部署
Web服务器: nginx
Web应用服务器:tomcat(2台)Nginx反向代理tomcat,即通过upstream将请求负载到后端两台tomcat的对应服务端口上。部署过程此处省略……
六、验证结果说明
1)设置tomcat1超时时间,造成超时状态(总有一台server为有效状态)
Tomcat1的connectionTimeout 设置为-1,永远超时,nginx设置tomcat1和tomcat2权重为10,tomcat1的max_fails为10,fail_timeout=120;在连接tomcat1的10次后,返回给nginx为10次超时,ngxin判断tomcat1为失效,然后将tomcat1超时时间恢复为1000重新启动tomcat1,在这段时间内nginx判断tomcat1还是失效状态,所以在2分钟后,nginx继续监听到tomcat1正常后,那么nginx会将tomcat1判断为有效,将连接继续均匀分配到2个tomcat上。2)设置tomcat1连接数量,造成超时状态(总有一台server为有效状态)
Tomcat1的线程数量设置为1,nginx设置tomcat1和tomcat2权重为10,tomcat1的max_fails为10,fail_timeout=120;在连接tomcat1超过线程接受数量后,tomcat1会返回超时状态,在返回给nginx10次超时状态后,ngxin判断tomcat1为失效,然后将tomcat线程数量恢复为700,重新启动tomcat1,在这段时间内nginx判断tomcat1还是失效状态,超过2分钟失效后,nginx继续监听到tomcat1正常后,那么nginx会将tomcat1判断为有效,将连接继续均匀分配到2个tomcat上。3)设置tomcat1关闭,造成拒绝状态(总有一台server为有效状态)
Tomcat1为关闭,nginx设置tomcat1和tomcat2权重为10,tomcat1的max_fails为10,fail_timeout=120;在连接tomcat1的10次后,nginx收到tomcat1返回connect refuse状态,ngxin判断tomcat1为失效,然后重新启动tomcat1,在这段时间内nginx判断tomcat1还是失效状态,超过2分钟失效后,nginx继续监听到tomcat1正常后,那么nginx会将tomcat1判断为有效,将连接继续均匀分配到2个tomcat上。4)设置tomcat1在nginx1标记失效,tomcat1恢复正常,在nginx失效范围内,将全部服务变为失效,然后重启
Tomcat1为关闭,nginx设置tomcat1和tomcat2权重为10,tomcat1的max_fails为10,fail_timeout=120;在连接tomcat1的10次后,nginx收到tomcat1返回connect refuse状态,ngxin判断tomcat1为失效,然后重新启动tomcat1,在这段时间内nginx判断tomcat1还是失效状态,然后将tomcat2关闭,然后重启tomcat2,由于所有服务均失效,所以nginx 将所有服务重新置为有效进行监听,然后将2连接均匀分布到了tomcat1和tomcat2上。5)http错误状态,nginx是否记录失效
nginx设置tomcat1和tomcat2权重为10,tomcat1的max_fails为10,fail_timeout=120;配置proxy_next_upstream 500、404、502、503、504、timeout后,当HTTP状态为500、502、503、504(timeout和refuse默认是记录失效的)时,nginx会判断该次请求为失败记录失败状态,其他所有HTTP均不记录失败。


Leave a Reply
Want to join the discussion?Feel free to contribute!